Сегодня компания Marvell совместно с тремя крупными производителями HBM — Micron, Samsung и SK hynix — делает следующий шаг в кастомизации XPU для гипермасштабируемых клиентов. Новая архитектура вычислений с использованием HBM от Marvell направлена на увеличение плотности HBM для XPU следующего поколения за счёт кастомизации интерфейса между HBM и XPU.
Кастомная архитектура вычислений Marvell HBM для гипермасштабируемых XPU
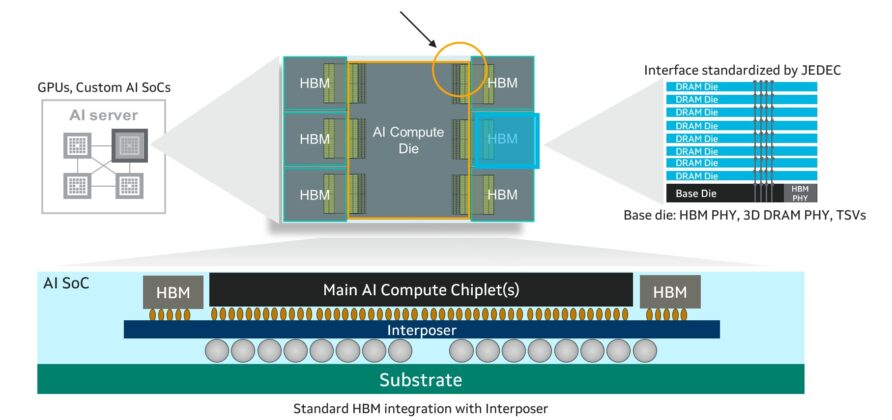
Память HBM жертвует ёмкостью и расширяемостью ради значительно более высокой пропускной способности. Обычно HBM размещается рядом с процессорами (CPU) и ускорителями (или XPU) и взаимодействует через стандартные проводники, проходящие через кремниевый интерпозер, который соединяет два кристалла. XPU обычно имеет два или более HBM-стека, состоящих из DRAM и базового кристалла.
Особенности архитектуры:
- Кастомный интерфейс:
- Marvell вместе с гипермасштабными клиентами и основными производителями HBM определяет новый интерфейс, который занимает меньше места на вычислительном кристалле. Это позволяет разместить больше HBM рядом с XPU, увеличивая пропускную способность и ёмкость памяти на один чип.
- Энергопотребление:
- Новый подход снижает требования к энергопотреблению для чипов, использующих кастомную память.

Преимущества кастомной архитектуры HBM
- Экономия пространства:
- Стандартный интерфейс HBM требует значительных площадей на кристалле, что ограничивает возможности его использования. Снижение физического пространства, необходимого для соединения HBM и XPU, освобождает место для дополнительных интерфейсов ввода-вывода или большего количества HBM.
- Увеличение производительности:
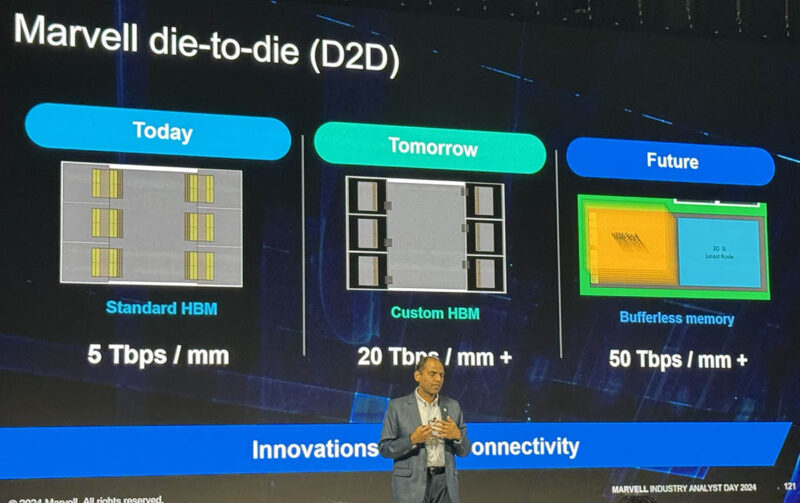
- Использование кастомного интерфейса увеличивает производительность ввода-вывода и снижает энергопотребление интерфейса на 70%.
- Кастомные функции:
- Новый интерфейс позволяет добавлять специализированную логику, такую как сжатие данных и функции безопасности.
- Увеличение пропускной способности:
- Marvell прогнозирует 4-кратное увеличение пропускной способности на квадратный миллиметр площади, с потенциалом увеличения до 10 раз в будущем.
Заключение
Для индустрии гипермасштабных вычислений это огромный шаг вперёд. Гипермасштабируемые компании в 2024 году вложили около $100 млрд в капитальные затраты. Следующее поколение кластеров для ИИ будет в 10 раз больше текущих, таких как кластер xAI Colossus на 100 000 GPU, потребляющий несколько гигаватт энергии. Экономия каждого ватта в масштабах таких систем выливается в мегаватты экономии. Отказ от стандартов JEDEC и переход к кастомным решениям для гипермасштабных клиентов показывает, что Marvell добилась значительных успехов в этой области, так как подобные разработки возможны только при крупных заказах.